

Hey — I’m Emily, your American accent coach. And if you’ve ever thought, “I can read English just fine… but when Americans speak, it turns into a blur,” you’re not alone. I hear this exact frustration from students every week.
Here’s the good news: the problem is usually not that Americans speak “too fast.”
The problem is that Americans speak connected.
They link words together, reduce small words, change sounds (hello, “t” ????), and package speech into rhythmic chunks. If you’re listening for “perfect dictionary words,” your brain can’t find the boundaries — so everything sounds like one long sound wave.
This guide will teach you a practical decoding system. Not “listen more.” Not “watch Netflix.” A real method you can use today.
And the biggest mindset shift?
Stop trying to hear every word.
Catch the stressed words first — then your brain fills in the rest. ????
Let’s name the real enemy: audio blur.
When you learned English, you probably learned it in a clean, separated way:
But real American speech is messy — in a predictable way.
Here’s what’s actually happening:
So if your listening strategy is “find every word,” your brain is doing an impossible job.
A better strategy is:
Find the meaning anchors first. (We’ll practice that a lot.)

American English is stress-timed — which means it runs on beats.
Think of stressed syllables like the beat in music. ????
They are the “anchors” your brain grabs to understand a sentence.
Most of the stress falls on content words:
And most function words get reduced:
Dictionary-style (what learners expect):
“I WANT to GO to the STORE.”
Real American speech (what you actually hear):
“I WANT tə GO tə thə STORE.”
Notice: the meaning words stay strong. The small words shrink into quick soft sounds (often schwa /ə/).
You are supposed to “miss” some sounds.
Not because you’re bad at English — because the language is designed that way.
Your job is not “hear everything.”
Your job is “catch the beats.”
Skilled listeners don’t track every word. They track:
If you listen word-by-word, speech feels like noise.
If you listen chunk-by-chunk, speech starts feeling like meaning.
In fast speech, Americans don’t leave clean gaps between words.
So your brain can’t answer:
“Where does one word end and the next begin?”
That’s why it feels like:
It’s not your ears. It’s your segmentation system (your brain’s “word-boundary detector”) needing retraining.
Try this:
If you can read it but you can’t hear it, that’s normal — it means you’re missing the fast-speech versions in your listening database.
We’re going to build that database.

This is the skill that changes everything.
When Americans speak fast, you want to catch 3–5 stressed words — like headlines.
Stressed words usually have:
Unstressed words are often:
While listening, aim to catch only the headline words.
Example:
Full sentence: “I’m gonna send you the updated file by the end of the day.”
What you should catch: send / updated / file / end / day
That is enough for meaning.
Example notes: send / file / end / day
Your brain can fill: “Someone will send a file later today.”
Do this with a friend, tutor, or even by yourself:
Your goal is not “perfect.” Your goal is “meaning.”
Many learners do this internally:
“Wait… was that can or can’t? Let me check… oh no, I missed the next sentence.”
That’s how you get lost.
New rule:
If you miss a word, keep moving. ????♀️
You’ll recover using anchors.
Fast speech becomes understandable when you stop hearing “words” and start hearing thought groups.
A thought group is a small meaning package — like a mini sentence inside the sentence.
Americans speak in chunks like:
These chunks are often said quickly — but as a unit.
Your brain has limited working memory. If you try to hold 12 separate words, it overloads.
But if you hold 2–3 chunks, it’s easy.
Take a short transcript and add slashes where you hear natural chunk breaks:
“I mean / if you want / we can do it tomorrow / no big deal.”
Then listen again and match the chunking.
Example: “I mean…”
Your brain predicts: “the thing is…” or “like…” or “it depends…”
This trains you to follow natural American speech patterns.
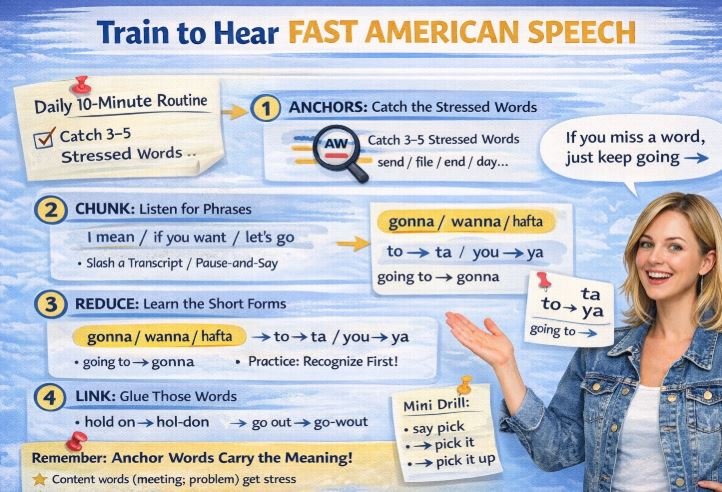
Here’s the toolkit. If you learn these five behaviors, “fast speech” stops being mysterious.
Americans don’t like “gaps.” They glue words.
If one word ends in a consonant and the next starts with a vowel, it links:
Mini drill:
Say it slowly, then link it:
When vowels meet, Americans often add a tiny glide:
Practice sentences:
Don’t force it too hard — it’s a gentle glide, like a bridge ????.
This is the #1 reason learners can’t “find” words they already know.
Common reductions:
Schwa /ə/ is the lazy, relaxed vowel. Americans love it in unstressed words.
That’s why:
Try these transformations:
A smart way to practice: recognize first, produce second.
Your listening improves faster when you can identify these forms instantly.
This is the classic “Americans don’t say T” misunderstanding.
In many positions, T and D become a flap /ɾ/ — a quick tap sound, like a soft “d.”
Examples:
Why learners lose the word: you’re listening for a crisp /t/ — but you’re hearing /ɾ/.
When do you usually get flap T?
Don’t panic — context usually makes the meaning clear.
Sometimes T doesn’t flap — it just disappears or becomes a throat “catch.”
Examples:
Don’t hunt for the T.
Instead, hunt for:
Example: “important”
If you hear: “im-POR-…” and the rhythm fits, your brain fills the missing T.
Sounds influence each other. This creates “new” forms.
Examples:
Also:
Again: recognition first. Production later. ✅
This is the big truth:
Your brain recognizes dictionary pronunciation…
but real life uses fast-speech pronunciation.
So even if you “know the word,” you don’t recognize it when it shows up in a new shape.
Start collecting the real-life versions you hear most often.
Here’s a starter list (save it somewhere):
Everyday reductions

Frequent “glue phrases”
The goal isn’t to memorize 1,000 forms in a day.
The goal is to start noticing them — and turning them into familiar friends instead of scary noise ????.
Captions can help — or they can trap you.
If you always watch with captions, your brain learns:
“I don’t need to decode sound. I’ll just read.”
So here’s the better method.
This trains your ears and keeps you from becoming dependent.
If you slow audio too much (like 0.5x), the rhythm changes and reductions become unnatural.
Instead, use:
Pick one sentence (5–8 seconds) and loop it 10–20 times.
Looping is not boring when you’re doing it with a mission:
Consistency beats intensity. Ten minutes daily is enough if you practice the right way.
Minute 1: Rhythm warm-up
Tap the beat while saying:
“I NEED to CALL you BACK.” (tap on NEED/CALL/BACK)
Minutes 2–3: Anchor capture
Listen to a short clip and write 3–5 stressed words.
Minutes 4–5: Chunking
Listen again and mark thought groups (slashes).
Minutes 6–7: One connected-speech pattern
Pick one: linking, reductions, flap T, dropped T, assimilation.
Minutes 8–10: Quick shadowing
Shadow the same clip (we’ll do this properly next section).
Pick audio that is:
Good sources:
Most people think shadowing is “pronunciation practice.”
But shadowing is also listening training — because it forces your brain to stay with the speaker in real time.
Shadowing is:
Shadowing is not:
Repeat 1–2 words behind the speaker.
Example:
Speaker: “So I was gonna call you…”
You (slightly behind): “…gonna call you…”
This trains real-time processing.
First, don’t try to copy exact sounds.
Copy only:
You literally “mumble” the shapes like:
“duh DUH duh DUH-duh…”
This removes pressure and builds the foundation fast ????.
Every week, test yourself with the same clip:
Progress often feels subtle — until one day you realize you’re understanding way more without trying.
Fast speech isn’t one thing. It changes depending on context.
More:
Listen for:
More:
Listen for:
Harder because:
Listen for:
When people get excited, they speed up and connect more.
Listen for:
Let’s fix the most common pain points.
That’s usually a reduction/connected-speech gap.
Fix:
That’s an anchor + chunking skill issue.
Fix:
That’s normal. Your brain is pattern-matching.
Fix: controlled exposure plan:
That means you have knowledge, not recognition.
Knowing a word on paper doesn’t mean recognizing it in a blur.
Fix:
Here’s a realistic plan that works if you stay consistent.
Daily:
Daily:
Daily:
Daily:
Yes — but slightly.
Use 0.85–0.9x, not 0.5x, so the rhythm stays natural.
Not required. IPA can help you notice patterns (like flap T), but you can improve a lot without it. If IPA stresses you out, skip it.
They’re not skipping meaning — they’re reducing unstressed parts to keep rhythm smooth. Stress carries meaning; reductions keep speed and flow.
If you practice 10 minutes a day with the system in this guide, many learners feel real improvement in 2–4 weeks — especially with anchor capture and reductions. Big jumps often happen around the 30-day mark.
Best choices depend on your goal:
Pick content you can loop without suffering ???? — repetition is the magic.
Understanding fast American speech is not a talent. It’s a trainable skill.
When you stop trying to hear every word and start listening for stress + chunks + patterns, your brain finally gets the clues it was missing.
So start simple:
Today: catch 3–5 stressed words from one short clip.
Tomorrow: add chunking.
This week: learn 10 common reductions.
Next week: flap T and linking won’t feel scary anymore.
And if you want extra structure, tools that let you loop sentences, track your improvement, and get feedback (including AI speech recognition + support from certified accent coaches) can make the process smoother — that’s exactly how programs like ChatterFox are designed to help, especially when you’re training both listening and speaking skills together. ????
You’ve got this. One “audio blur” at a time.

